
Deep Learning is introduced in this page. Although it is not complete as of yet, the links provided in this page are hot and the materials there are genuine and could be very useful to know about the deep learning.
Computer vision is a field in computer science. It looks like CV’s current objective is to recognize an object in images. They are solving object recognition problems.
Seeing with your tongue (inside Andrew Ng’s talk)
Convolutional networks.
Rectification layer.
Google Brain is an unofficial name for a deep learning research project at Google.
Deep learning portal
-
Deep Learning—moving beyond shallow machine learning since 2006. https://deeplearning.net
Tutorials:
-
Ivan Vasilev, “An introduction to Deep Learning: From Perceptrons to Deep Networks,” https://www.toptal.com/machine-learning/an-introduction-to-deep-learning-from-perceptrons-to-deep-networks. This one is very illustrative and easy-to-follow.
-
Rob Fergus, “NIPS 2013 Tutorial – Deep Learning for Computer Vision,” https://www.youtube.com/watch?v=qgx57X0fBdA, Lake Tahoe, USA.
Names to note:
-
Geffrey Hinton, Professor of U Toronto, now working also at Google, Inc. His web-page has papers on the fast learning algorithm and MATLAB files. https://www.cs.toronto.edu/~hinton/.
-
Geoffrey Hinton, Recent Developments in Deep Neural Networks, UBC Computer Science Distinguished Lecture Series, May 30, 2013, https://www.youtube.com/watch?v=vShMxxqtDDs.
-
Stanford Professor Andrew Ng,
Deep Learning, Self-Taught Learning and Unsupervised Feature Learning, https://www.youtube.com/watch?v=n1ViNeWhC24
Machine Learning (free online course on Coursera)
Andrew Ng is Associate Professor of Computer Science at Stanford; Chief Scientist of Baidu; and Chairman and Co-founder of Coursera.
In 2011 he led the development of Stanford University’s main MOOC (Massive Open Online Courses) platform and also taught an online Machine Learning class to over 100,000 students, leading to the founding of Coursera. Ng’s goal is to give everyone in the world access to a gret education, for free. Today, Coursera partners with some of the top universities in the world to offer high quality online courses, and is the largest MOOC platform in the world.
Ng also works on machine learning, with an emphasis on deep learning. He had founded and led the “Google Brain” project, which developed massive-scale deep learning algorithms. This resulted in the famous “Google cat” result, in which a massive neural network with 1 billion parameters learned from unlabeled YouTube videos to detect cats. More recently, he continues to work on deep learning and its applications to computer vision and speech, including such applications as autonomous driving.
Spletna stran uporablja Ali lahko Sildenafil 100 mg nabavite brez recepta? piškotke za izboljšanje uporabniške izkušnje. Izkušnje uporabnikov so izjemno pozitivne zaradi sestave na naravni osnovi, ki vsebuje zelo potentne ter stimulativne snovi. Ni minilo dolgo, mogoče kako urico, ko sem začutil, nekako toplino, prav prijetno mi je bilo. V poštev pride predvsem pri moških, ki so pogosteje spolno aktivni in si želijo spontanosti ter ne želijo jemati tablet tik pred spolnim odnosom. Paket vam pošljemo na način poštno ležeče, kar pomeni, da na dom tako ne prejmete nobenega obvestila o čakajoči pošti.
-
Feature learning via Sparse Coding
-
-
Papers on deep learning:
-
G. E. Hinton and R.R. Salakhutdinov, “Reducing the Dimensionality of Data with Neural Networks,” Science, Vol. 313, July 28th, 2005. https://www.cs.toronto.edu/~hinton/science.pdf
-
Hinton, G. E., Osindero, S. and Teh, Y. (2006), A fast learning algorithm for deep belief nets. Neural Computation, 18, pp 1527-1554. [pdf]
Movies of the neural network generating and recognizing digits
-
이성규기자, 요즘 뜬다는 ‘딥러닝’, 대체 그게 뭐지, https://news.zum.com/articles/15156572.
Recap of Ivan Vasilev’s Tutorial
- A single neuron from a supervised learning perspective: suppose there are n vectors, each comes with label 0 or 1. A new vector is given, and the aim is to label the new vector.
For this problem, a linear classifier can be defined. The linear classifier comes with a separator – a hyperplane —which divides the vector space into two, above and below the plane. The hyperplane can be described as
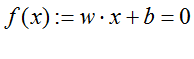 which is fully defined once the weight vector
which is fully defined once the weight vector 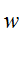 and the bias
and the bias  are determined. Using the n vectors, one can train function. An algorithm such as the support vector machine can be used to obtain the optimal weight vector w and bias. The neuron can be made to fire, generates ‘1’, when
are determined. Using the n vectors, one can train function. An algorithm such as the support vector machine can be used to obtain the optimal weight vector w and bias. The neuron can be made to fire, generates ‘1’, when  , ‘0’ otherwise. A nonlinear activation function such as tanh, binary, and rectifier can be used for learning a non-linear function.
, ‘0’ otherwise. A nonlinear activation function such as tanh, binary, and rectifier can be used for learning a non-linear function.
-
The figure above shows a single perceptron. A single perceptron has a drawback: it can learn only linearly separable functions.
-
Now imagine a combination of perceptrons connected back to back as shown below. It is called Feedforward Neural Network

-
The network can be trained via the so-called backpropagation. The basic procedure is to propagate the training input in forward manner, calculate the output errors starting at the output node, adjust the weights and biases of all one immediate previous nodes each in the stochastic gradient decent way, and repeat this error calculation and adjustment procedure to next layer of upstream neighbors.
-
Hidden layers are very important. It seems that there exists a theorem, universal approximation theorem, which states that a single hidden layer with a finite number of neurons can learn any arbitrary function. More layers could be utilized to learn things better. The hidden layers stores abstract information of the raw training data similar to way that the human brain has an internal representation of the real world. With deeper nets, however, there are issues with vanishing gradients and overfitting.
-
Autoencoders is feedfoward neural network which aims to learn a compressed encoding of a dataset. The output is a recreated version of the input. The target data should be the same as the input. A few small nodes in the middle is to learn the data at a conceptual level and gives a compact representation of the core features of the input.
-
Restricted Boltzmann Machines. It is a generative stochastic neural network that can learn a probability distribution over its set of inputs. An RBM is made of a visible, hidden, and bias layer. Just like the graph decoding for LDPC codes, the connections between the visible and hidden layer are bi-directional and the message can be flowing from visible to hidden and from hidden to visible. The graph is not fully connected in general, hinting the name “restricted.” The standard RBM generates binary 0/1 outputs.
-
RE