
[AI-post 4] Anomaly Detection method via GAN (posting date : 190529)
이번에는 [AnoGAN]에 대한 아이디어를 최대한 수식 없이 풀어보고자 합니다.
- GAN 기본에 대해 아시는 분은 Chap 3 부터 읽으시면 되겠습니다.
<요약>
본 논문에선 다음을 내용에 대해 이야기하고자 합니다.
- GAN 이용한 특수 응용 사례 : Outlier detection (Classifier 에 학습되지 않은 data에 대한 검출 방법)
– 일반적으로 Classification system 에서 학습되지 않은 형태의 Data가 입력될 경우 ‘학습되지 않은 Data‘임을 알아내는 것은 매우 중요하나, 쉬운 문제는 아니라서 많이들 간과하고 있음.
(e.x. ‘개/고양이’ 사진을 분류하는 시스템에, ‘사람’ 사진이 입력될 경우, ‘개/고양이가 아님’이 아닌 ‘개’ 또는 ‘고양이’중 하나로 분류함.)
– 본 포스팅에서는 상기 문제를 해결을 위해 idea 측면에서 이야기 하고자 함.
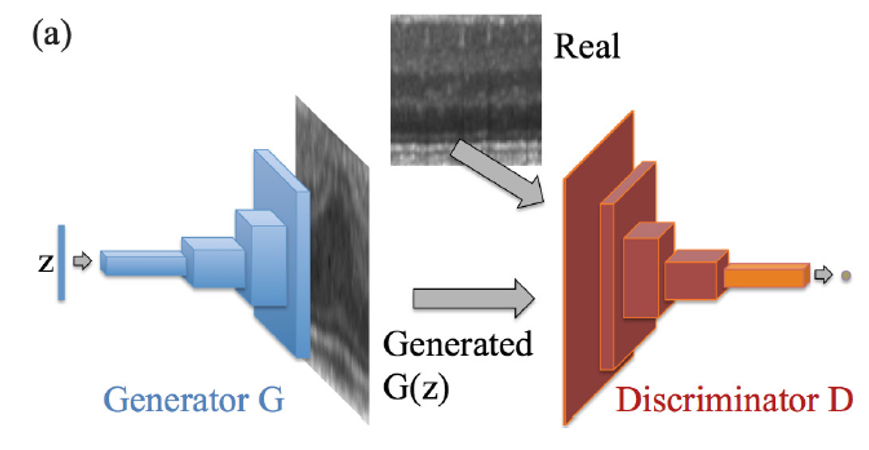
[GAN] Chap 1.> GAN이란 ?
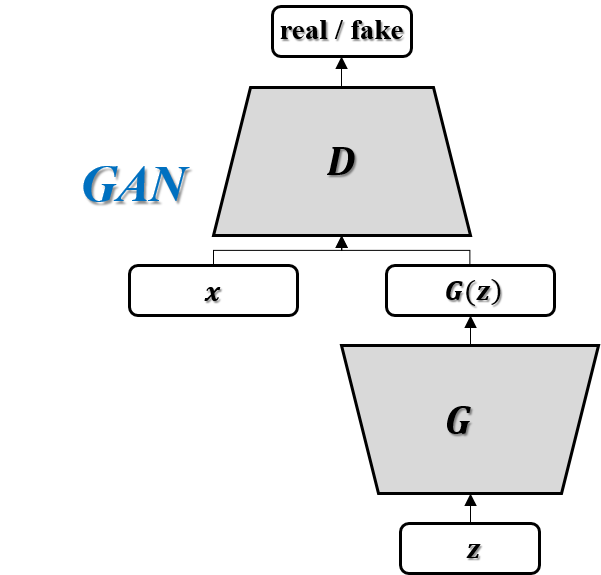
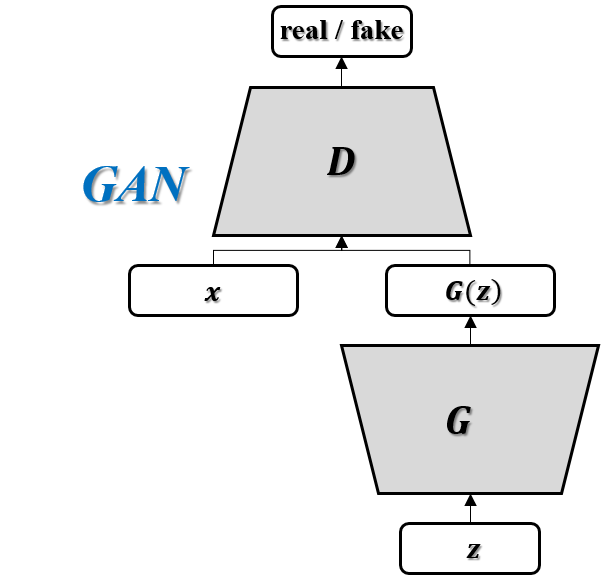
GAN은 Generative Adversarial Networks (GAN)의 약자로서, 2014년 NIPS 에서 Ian J. Goodfellow 에 의해 발표되었습니다.
오른쪽 그림은 GAN의 일반적인 Architecture를 나타내었습니다.
Generator (G) 의 목적은 임의 벡터 z를 통해 생성되는 G(z) 이미지를 최대한 원래의 이미지인 ‘x’와 비슷하게 만드는 것이 목표이며 (최대한 비슷하게 만들어 Discriminator를 속이고자 하는것)
Discriminator (D) 의 목적은 Real image인 ‘x’와, Fake image인 ‘G(z)’를 정확하게 구분하고자 하는 것입니다.
([GAN] 논문에서 나온 예시입니다. “위조지폐범(Generator)은 최대한 위조지폐를 잘 만들어 경찰관(Discriminator)를 속이고 싶어한다 생각하며, 경찰관(Discriminator)은 이를 방지하고 싶어한다” 로 생각하면 이해가 쉬우실 겁니다.)
이 때 D 와 G를 서로 대립하게 두어 학습시킨다는 의미에서 Adversarial training 이라 불리며, 다음의 Cost function 을 기반으로 Minimax game 을 만들어 풀게 됩니다.
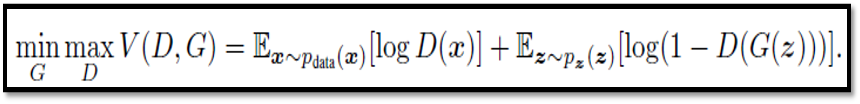
[DCGAN] Chap 2> DCGAN이란 ?
DCGAN이란, Fully connected layer 로 구성된 GAN에서 D와 G를 Deep Convolutional network 를 통해 구현한 논문입니다.
아이디어 자체는 간단합니다. 다만, 여러 모종의 이유로 Conv. layer 구현 시 GAN 이 안정적으로 학습되지 못하는 문제가 존재 했었는데, 이를 해결하고 그에 따른 일반적인 학습론을 제시했다는 점에서 많은 주목을 받았습니다.
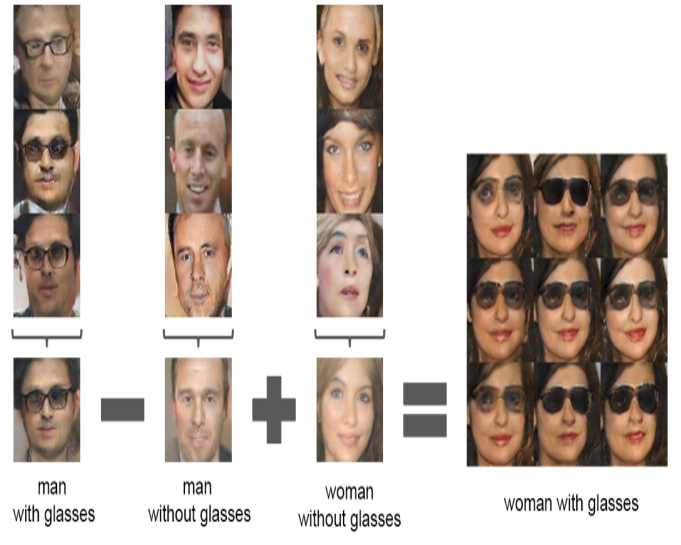
DCGAN 결과 중 재밌는 점이 있어 짚고 넘어가고자 합니다. (오른쪽 그림)
학습된 latent vector ‘z’에 대한 Vector calculation 이 가능하다는 점 인데요, 그 전까지 단순히 Image generation 측면에서 바라보던 관점에서, 정확한 의미 (with Glasses와 같은) 가 학습되는 것을 보였다는 점에서, DCGAN이 각광을 받는다 생각하시면 되겠습니다.
<<이제 우리는 ”GAN 및 DCGAN을 통해, latent space Z와 Image space X 사이의 mapping function 을 구하는 방법”에 대해 알게 되었습니다.>>
Chap 3> Anomaly Detection 입장에서의 GAN 주요 기능
왜 Anomaly detection 을 한다면서, 자꾸 image regeneration 만 다루는지 의아하실 수 있습니다.
여기서 한번 GAN의 주요 기능을 정리하자면 다음과 같습니다
- Real image set (X)와 최대한 유사한 이미지 G(z)를 만들어 내는 것
혹은 이를 다시 생각하면
- 잘 학습된 GAN을 통해 생성된 이미지 G(z)는, 충분히 Real image (x)와 유사하다 (동일하다).
로 생각하시면 되겠습니다.
두번째 줄에 대한 의미는 뒤에 다시 말씀드리겠습니다.
[Image inpainting] Chap 4> Mapping the new images into latent space Z
이제부터 AnoGAN에 대한 이야기를 시작하기에….. 앞서!!
AnoGAN의 Key idea에 대해 잘 설명된 타 논문이 있어, [Image inpainting] 내용을 소개시켜드리고자 합니다.

풀고자 하는 문제는 다음과 같습니다.
‘영상 내 부분 Making 이 된 input ‘y’가 들어왔을 때, masking 된 영역에 대한 그리기(inpainting)를 수행하여 원본 사진을 추측하기’
위 문제를 다음의 과정을 통해 풀게 됩니다.
- Step 1> 사람 얼굴 영상에 대해 DCGAN을 자…알! 학습하기 (G와 D를 학습하기) => GAN 학습 완료
- Step 2> 임의의 random 한 latent vector ‘z1’을 선택하여 GAN을 이용해 복원하기 (G(z1))
- Step 3> Masking 된 영상 ‘y’와, 복원된 영상 ‘G(z1)’의 차이 (Loss function Lp, Lc)를 계산하기
- Step 4> Loss에 대한 Gradient Decent 를 latent vector ‘z’에 대해 수행하기
(혹은 G와 D를 고정하고, 더 작은 loss를 보여주는 ‘z’를 찾는 것 으로 이해하셔도 됩니다.) - Step 5> 정의된 itteration 횟수만큼 step 2~4 반복
정리하자면 다음과 같습니다.
- 잘 학습된 GAN을 통해 Real image space 를 얻고
- Query image (masking 된 얼굴 영상) 가 들어왔을 때, 차이 (loss fn)를 계산하여 가장 비슷한 사진을 찾는다.
상기 그림의 (b) 에서, 파란색 화살표의 의미를 생각해보시면 되겠습니다.
<<이제 우리는 ”잘 학습된 GAN에서의 image space 속에서, 새로운 image가 들어왔을 때, 가장 비슷한 놈을 찾는 방법”에 대해 알게 되었습니다.>>
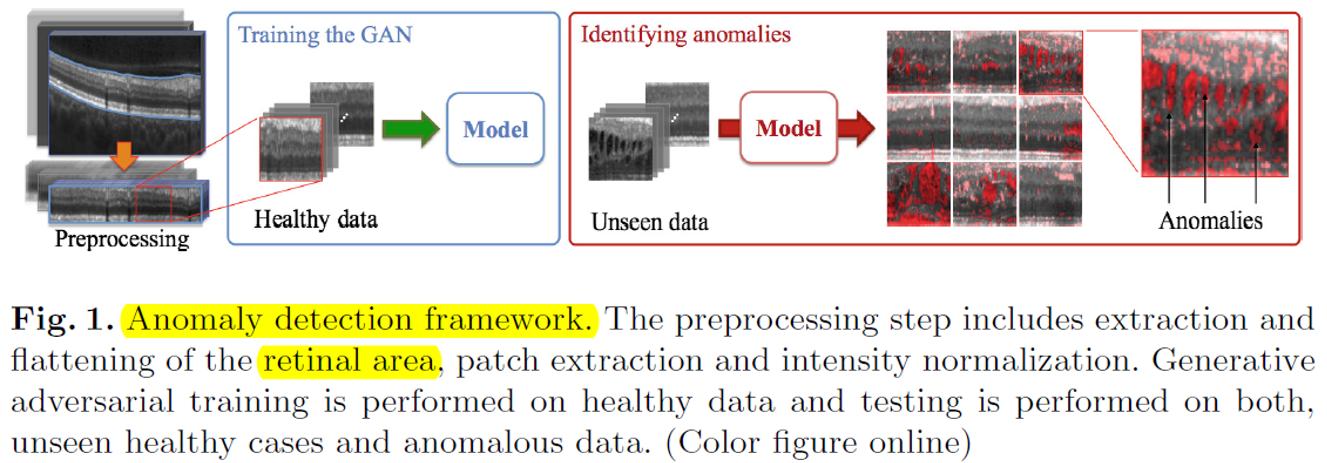
[AnoGAN] Chap 5> Anomaly Detection method via GAN
사실 AnoGAN의 key idea는 다음과 같이 정리할 수 있습니다.
- Image domain에 대해 잘 학습된 DCGAN과 (Chap 1,2)
- 새로운 Image가 들어 왔을 때 가장 비슷한 놈을 찾는 방법 (Chap 4)
- 찾은 비슷한놈과 비교하여 Anomaly detection 을 수행하는 방법 (Chap 5)
이제 각각의 idea에 대해 설명해 보겠습니다. (드디어 시작이다 ㄷㄷㄷ)
idea 1) Image domain 에 대해 잘 학습된 DCGAN과 (Chap 1,2)
사실 idea1은 chap 1~2에서 설명한 방법을 통해, DCGAN을 잘 학습시키는 것이 전부입니다.
단지, 이때 training data 는 건강한 사람들의 retina에 대한 의학 단층 영상 이며
훈련된 DCGAN의 목표는 ‘건강한 retina 단층 영상’을 잘 만들어내는 것 이라는 점이 다르다고 보시면 되겠습니다.
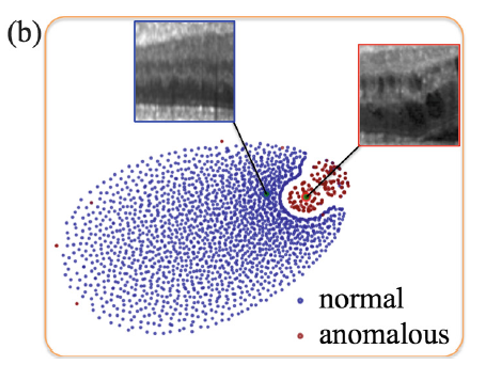
idea 2) 새로운 Image가 들어 왔을 때 가장 비슷한 놈을 찾는 방법 (Chap 4)
오른쪽 그림은, idea 1을 통해 학습된 Manifold region을 타나냅니다.
학습된 영상들에 대한 latent vector z 에 대해 t-sne 를 통해 눈으로 볼 수 있게 가시화 시킨 것으로 생각하면 되겠습니다.
idea 2에서는 chap 4와 같이 test sample이 주어졌을 때, 가장 가까운 feature point 를 찾아내는 과정입니다.
세부적으로 다음과 같습니다.
- Step 1> Healthy retina image DCGAN을 잘 학습하기.(G와 D를 학습하기) => GAN 학습 완료
- Step 2> (Test sample 입력 시) 임의의 latent vector ‘z1’을 선택하여 GAN을 이용해 복원하기 (G(z1))
- Step 3> Test sample ‘y’와, 복원된 영상 ‘G(z1)’의 차이 (Loss function Lp, Lc) 계산하기
- Step 4> Loss에 대한 Gradient Decent 를 latent vector ‘z’에 대해 수행하기
(or G와 D를 고정하고, 더 작은 loss를 보여주는 ‘z’를 찾기) - Step 5> 정의된 iteration 횟수만큼 step 2~4 반복 (논문에선 500번..)
<contributions> 이때 AnoGAN에선 조금 더 좋은 영상을 찾기 위해 Loss function 을 다음과 같이 정의하고 있습니다.
Residual loss
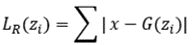
> x와 G(zi)간의 시각적 차이 측정을 위함
[Proposed] Improved Discrimination Loss based on Feature Matching
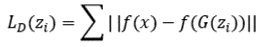
> f(.) : Discriminator 중간 층에 대한 Feature map (Activation)
> x와 G(z)에 대한 activation function 단에 대한 오차를 cost로 계산하는 과정
> [Feature matching] Classifier 구현 시, Output (Probability)에 대한 단순 Cross entropy를 구하는 것 보다, 중간 Activation 에서의 차이를 cost로 이용하면 더 학습이 잘된다는 개념
(혹은 x와 G(z)가 유사하다면, Classifier 중간 activation 역시 유사할 것이다 로 보는 관점도 있습니다.)
Total Loss Function
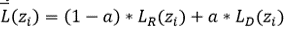
이렇게 정의된 loss fn. 을 통해 찾아진 GAN의 출력 영상 (G(z500)) 은 이제 입력된 test sample 과 유사한 유전적 특성을 지닌 건강한 사람의 retina image로 여겨지게 됩니다.
idea 3> 찾은 비슷한놈과 비교하여 Anomaly detection 을 수행하는 방법 (Chap 5)
저희는 아직 Anomaly detection 관점에서의 방법은 이야기를 드리지 못했습니다.
다만
- chap3 에서 ‘GAN을 통해 생성되는 image는 충분히 realistic 하다’와
- idea2 에서 ‘(이상한) test sample 이 입력 됬을 때, GAN 의 image space 중 가장 유사한 건강한 retina image를 찾는다’에
대해서 이야기 했습니다.
때문에 다음과 같이 정리할 수 있게 되었습니다.
‘Unhealty image 가 주어졌을 때, idea 2를 통해서 GAN을 통해 가장 Healthy 한 image를 찾고 그 둘을 비교하여 Anomaly 를 찾기 ‘
여기서 재밋는 것은, 이미 idea 2에서 이미 입력된 영상과 GAN을 통해 만들어진 영상간의 차이를 반복적으로 계산했다는 점 입니다. (i.e. Loss function)
때문에 저자는 Anomaly score를 다음과 같이 정의하였습니다.
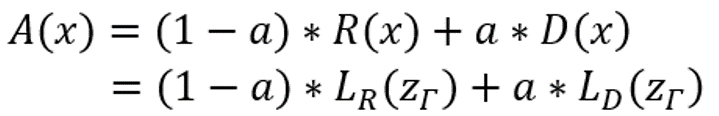
여기서 A(x)는 anomaly score 이며, R(x) 는 Residual score, D(x)는 Discriminator score로 정의되며,
이는 idea2를 통해 찾아진 최종 image(G(z500))와 입력 영상간의 차이를 계산하는 과정으로 생각하시면 되겠습니다.
또한 저자는 영상 내 anomaly region 에대한 segmentation 을 위해, 다음과 같이 정상 사진과 unhealty 사진간의 차이를 계산하였습니다.
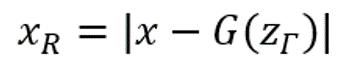
<<이제 우리는 ‘‘GAN을 이용하여 Anomaly detection을 수행하는 법”에 대해 알게 되었습니다>>
Chap 6> 실험 결과
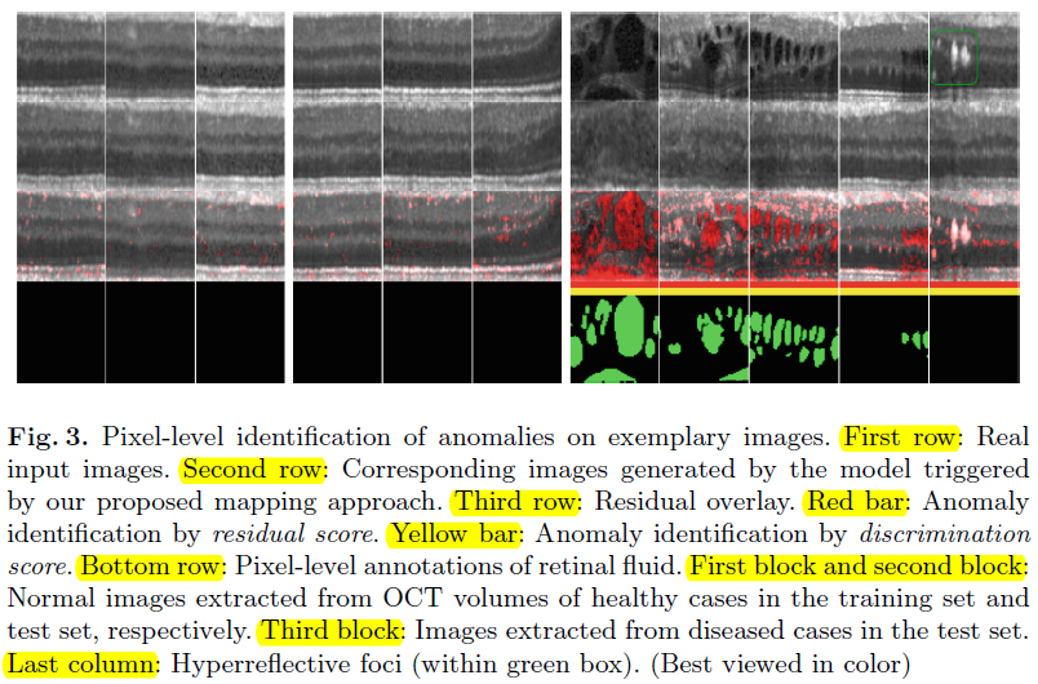
제안하는 시스템에 대한 실험 결과입니다.
- 1st row 가 (충분히 학습된 GAN에 대해) Query image로 입력되는 Test data이며
- 2nd row 가 idea 2를 통해 얻어지는 G(z500) 영상이 되겠습니다. (건강하다고 여겨지는)
- 3rd / 4th row 의 경우, idea 3에 의해 측정되는 Anomaly detection region 및 그에따른 전문가 annotation label 결과가 되겠습니다.
실험 결과, 충분히
- (1~6 col) Healthy 한 영상에 대해서는 충분히 realistic 한 영상을 출력해 주는 것을 확인할 수 있었으며
- (7~11 col) Unhealthy 한 영상에 대해서는 비교되는 healthy 영상을 출력하고 이에따른 Anomaly segmentation 결과가 실제 label과 유사함을 확인할 수 있었습니다.
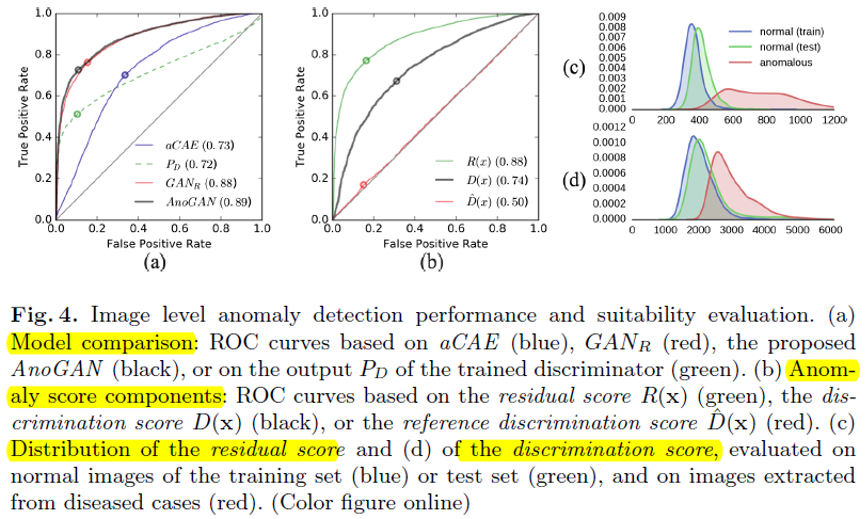
[a, b figure] Anomaly detection 은 결국 Pixel by Pixel classifier 로서 동작하다 보니, 제안하는 시스템에 대한 ROC curve 및 AUC 값을 구한 결과입니다.
보통 ROC curve 가 1/2 지점보다 높게 위치할 수록, 그에 따른 AUC 값이 클수록 좋은 classifier 라 볼 수 있는데, 제안하는 시스템이 가장 좋은 성능을 보임을 확인할 수 있었습니다.
[c, d figure] 또한 Anomaly detection score 에 대한 histogram 을 그려 보았을 때, Unhealthy (red) data에 대한 distribution 이 다르게 분포하여, 충분히 분류 가능함을 확인할 수 있었습니다.
Chap 7 > 결론
저자는 AnoGAN으로 명명된 시스템을 제안하고, 이를 통해 retina image에 대한 anomaly detection 을 훌륭하게 구현해 내었습니다.
일반적으로 Classification system 에서, 학습 DB 속 포함되지 않은 data가 입력되었을 때 어떻게 대처해야 할 지는 매우 중요한 문제이나, 역설적으로 풀기 쉬운 내용은 아니라서, 많이들 (논문에서) 간과하는 부분이 있는 것 같습니다.
사람들이 직접 설계하는 handmade feature가 아닌, Bigdata 속 nonlinear feature를 직접 뽑는 데 특화된 deep learning 을 이용하여 비학습 데이터에 대한 warning marker를 계산해 내었다는 점에서 매우 흥미로웠으며, 본 아이디어가 제 연구 뿐만 아닌 연구실 내 Deep learning structure를 이용중인 (예정중인) 분들에게도 도움이 될 내용으로 판단되어 본 포스팅을 작성하게 되었습니다.
p.s. 1: 쓰다보니 무진장 길어져버렸네요….. 다음번 포스팅은 훨씬 줄이는걸로… hahah 🙂
p.s. 2: 본 논문과 같은 목적이지만 조금 더 (많~이) 복잡한 구조를 지닌 다음 논문을 포스팅…. (해야하는데… hmm) 예정입니다 🙂
[Next] Diego Ardila, et.al., ‘End-to-end lung cancer screening with three-dimensional deep learning on low dosechest computed tomography’ Nature medicine, 2019
<References>
[AnoGAN] Thomas Schlegl, et.al., ‘Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discover’, IPMI 2017
[DCGAN] Alec Radford, Luke Metz and Soumith Chintala, ‘Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks’, ICLR 2016
[GAN] Ian J. Goodfellow, et.al., ‘Generative Adversarial Networks’, NIPS 2014
[Image Inpainting] Raymond A. Yeh, et.al., ‘Semantic Image Inpainting with Deep Generative Models’, CVPR 2016