아래 UI들은 학습 시킨 모델들을 보여주기 위해 Gradio라이브러리를 사용한 것이며, 모델학습 또는 소유에 대한 것은 연구실에 있음.
- Problem Statements
-
유효기간 관리:
- AI가 자재의 유효기간을 추적하고, 생산 과정 전체에서 유효한 자재만 사용되도록 관리해야 함.
-
자재 대체 처리:
- 생산 중간에 특정 자재가 다른 자재로 대체될 경우, SAP는 이를 효과적으로 반영하지 못함. AI는 대체 자재를 인식하고, 변경된 자재가 생산 요건을 충족하는지 확인할 수 있어야 함.
-
재고 관리:
- 창고 점유율을 예측하고, 최적의 재고 관리가 가능하도록 지원해야 함.
-
유효기간 관리:
- Famous model Inferencing and UI (URL)
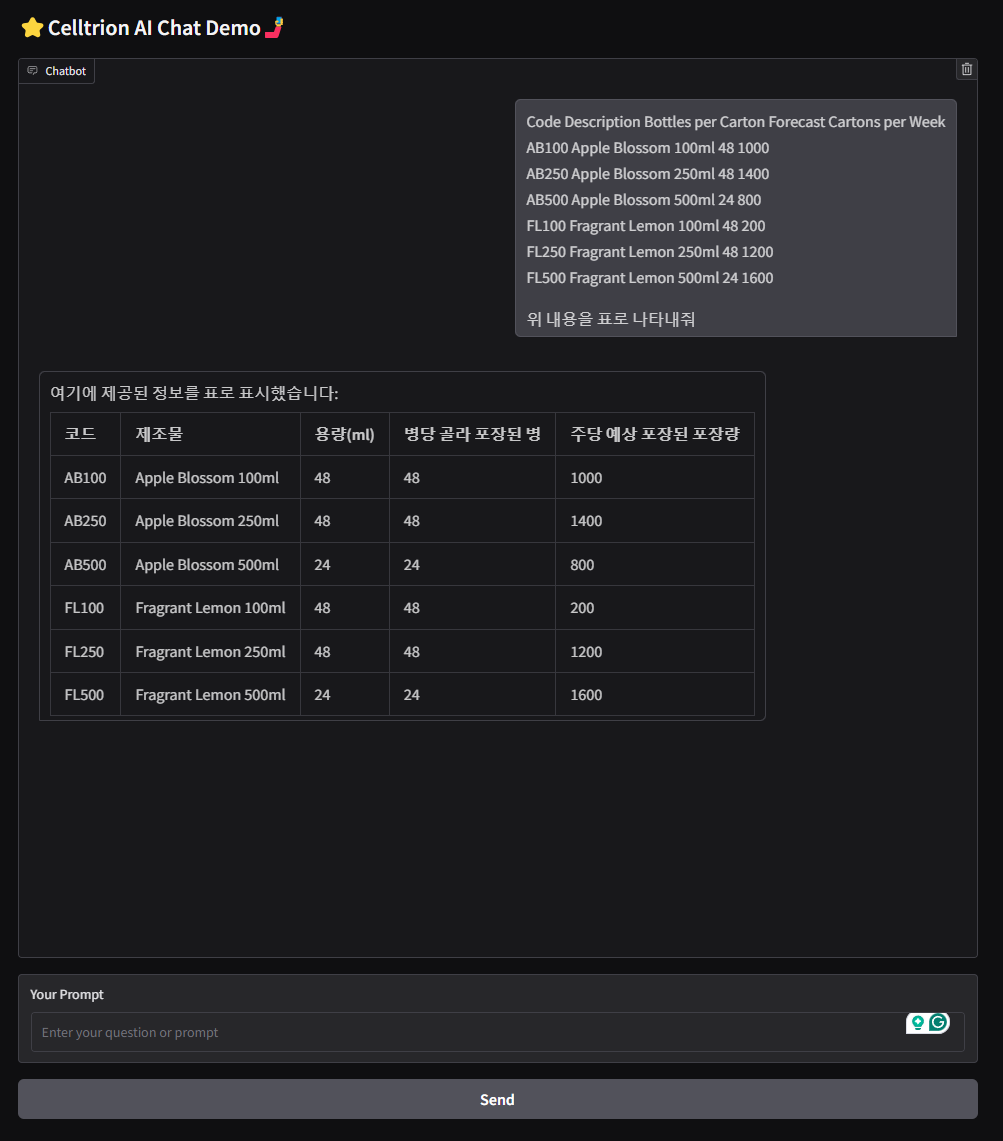
- Training model with Korean Legal Query Dataset (URL)
-
Overview
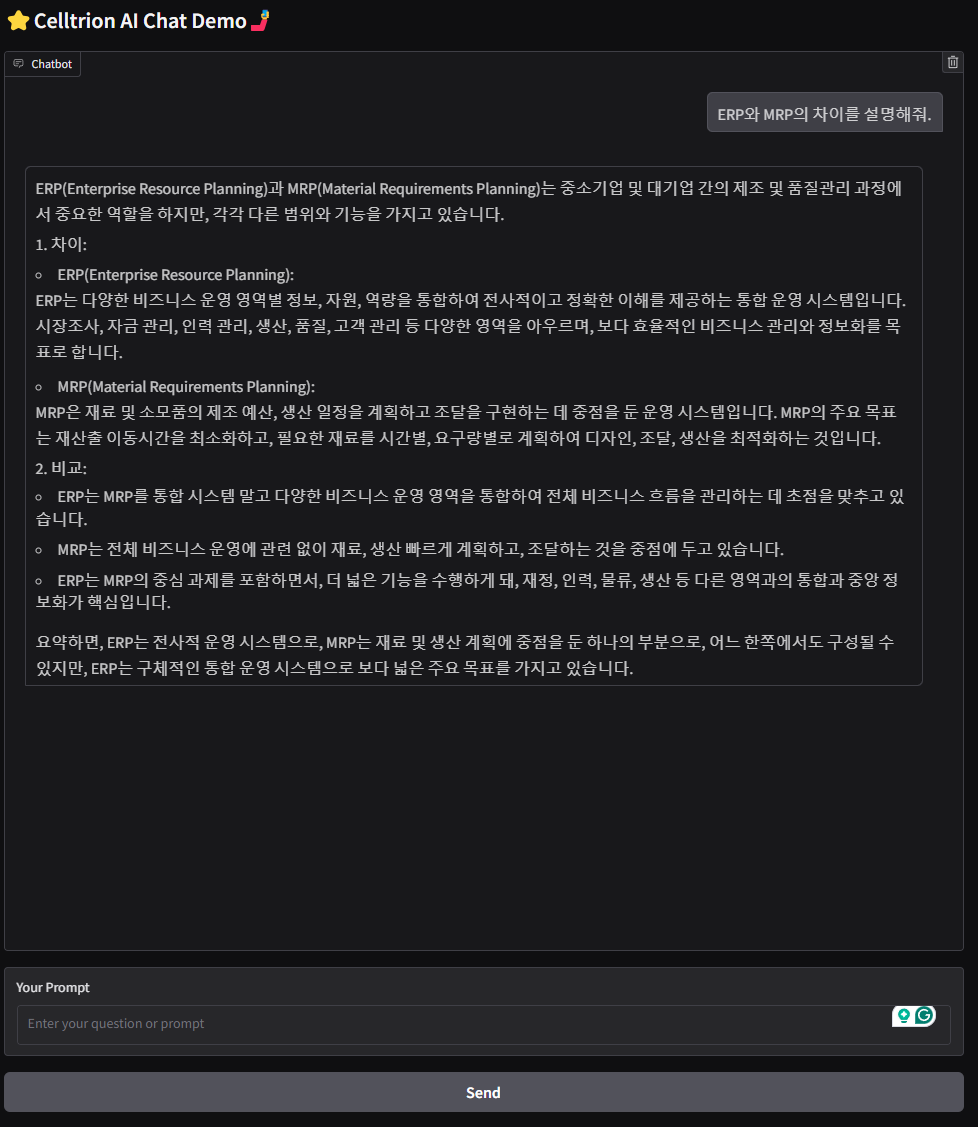
This chatbot service is based on Language model which is specialized in Korean legal field to provide user quick legal assistance. It can offer real-time responses to a wide range of questions. With its ability to understand and interpret complex legal terminology, it ensures that users receive clear and understandable information.
Fine-tuning with Korean Law
KLQD (Korean Legal QA Dataset) is a large-scale dataset constructed by collecting legal QA data from multiple platforms, refining it through preprocessing and expert verification, and categorizing it into nine major legal domains to ensure accuracy and applicability.
By prioritizing real-world legal inquiries, it enables AI models to provide accurate and accessible legal guidance. Multiple AI models, including LLaMA-3.1 and Gemma-2, were fine-tuned using KLQD, resulting in significant improvements in legal comprehension, contextual reasoning, and response accuracy.
To operate the demo in this page, we fine-tuned a model and uploaded it on Huggingface so that it can be accessible publically. The model has 8B parameters, which is relatively small, to run the model on small GPU.
How to Use Figure: System UI of Korean Legal Model Service
Figure: System UI of Korean Legal Model Service
To interact with the system effectively, access the provided URL and follow these steps.
Submit Your Query – Enter simple question that related to law in the input field and click “Send” button to initiate the response generation process.
Check the Output – The model will respond to your query which will be shown on the chat field. If you have another query to ask, do the same as Step a. The model would give a response based on the previous chat history.
-
Overview
- A Comprehensive Report on Legal Query RAG (URL)
-
Overview
Legal Query RAG (LQ-RAG) is an advanced Retrieval-Augmented Generation (RAG) system designed specifically for legal domain Q&A. It enhances traditional RAG approaches by integrating an agent-based iterative refinement mechanism. During inference, it first generates an initial response to a user query and then utilizes an evaluation agent to assess its quality based on contextual relevance and factual grounding. If the response does not meet predefined criteria, the evaluation agent provides feedback to the prompt engineering agent, which modifies the query to improve the next response. This iterative feedback loop continues until the evaluation scores approach optimal values.
-
Overview
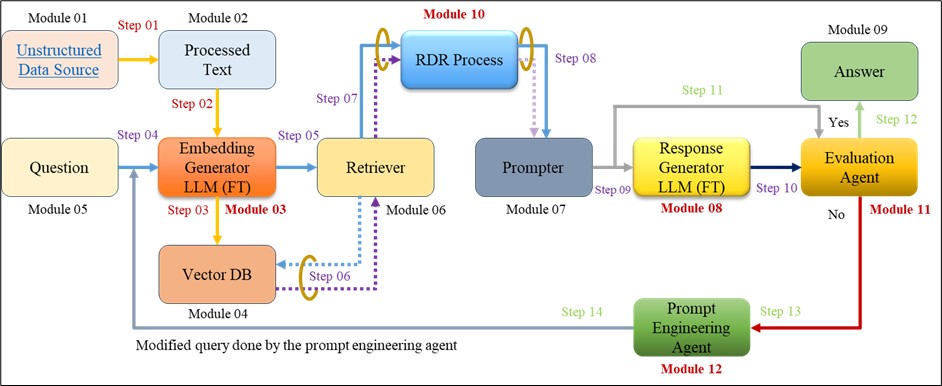
Figure: Proposed LQ-RAG System Architecture
- Data Ingestion: Step 1 > Step 2 > Step 3.
- Initial Response Generation: Step 4 > Step 5 > Step 6 > Step 7 > Step 8 > Step 9 > Step 10.
- Evaluation Agent Assessment: Step 10, 11 if condition Yes then Step 12 otherwise Step 13.
- Query Modification & Reprocessing: Step 13 > Step 14 then follow Query and Response Flow & Evaluation Flow.
- How LQ-RAG Works?
-
Data Ingestion – Related document need to upload in the system to do vectorization and store the vectorized data in a vector database.
- Initial Response Generation – When a user submits a query, LQ-RAG first generates a response using its retrieval and generation components.
- Evaluation Agent Assessment – The response is assessed by an evaluation agent that measures its contextual relevance and factual grounding against retrieved documents.
- Query Modification & Reprocessing – If the response fails to meet predefined criteria, the evaluation agent provides feedback to a prompt engineering agent. The prompt engineering agent refines the query and submits it again, iterating the process. This feedback loop continues until the response reaches an acceptable quality threshold, ensuring that the final output is relevant, factually accurate, and legally grounded.
- Models Used in LQ-RAG
LQ-RAG utilizes four different models to ensure high-quality legal query processing. For embedding generation, it employs a fine-tuned version of GIST Large Embedding v0, enabling efficient document retrieval from user-provided documents. The response generation model is based on LLaMA-3-8B, fine-tuned using Supervised Fine-Tuning (SFT) to enhance its ability to handle legal queries and generate accurate responses. To ensure response accuracy and reliability, GPT-4 is used as the evaluation agent, leveraging Chain-of-Thought (CoT) reasoning to assess contextual relevance and factual grounding against retrieved documents. Additionally, for prompt engineering, LLaMA-3.1-8B-Instant is utilized to iteratively optimize and reformulate queries, improving response quality. This combination of models enables LQ-RAG to generate factually grounded, contextually relevant, and high-quality legal responses.
- How to Use the System:
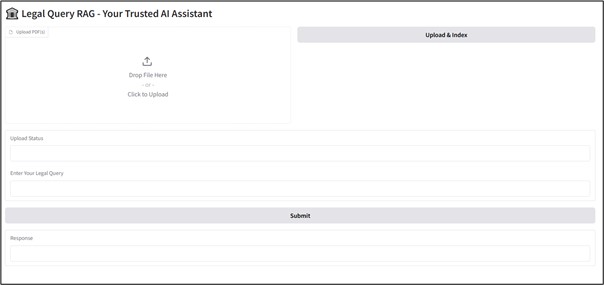
Figure: Proposed LQ-RAG System UI
To interact with the system effectively, access the provided URL and follow these steps
-
Upload a PDF Document – Begin by uploading a document that contains relevant legal information. Click the “Upload & Index” button in the top right corner to index the document and store it in the vector database.
- Submit Your Query – Enter your query in the input field and click the “Submit” button to initiate the retrieval and response generation process.
- Test General Queries – You can also ask questions unrelated to the uploaded document to assess how the system responds to broader legal inquiries.
- Expected Output:
-
Case 01: If the query is related to the uploaded document and the generated response meets the evaluation criteria defined by the evaluation agent, the final response will be displayed in the Response field.
-
Case 02: If the response fails to meet the evaluation criteria after three iterations, the system will return a default message in the Response field:
“⚠️ Sorry, we couldn’t find your answer.”
-
Case 03: If the query is outside the scope of the uploaded document or system is unable to extract related documents, the system will generate a default LLM-based response along with a warning:
“⚠️ Warning: The response is generated by LLM. The provided document does not contain enough information about the query. This response may not be fully accurate.
Final Response: …”
-
Case 02: If the response fails to meet the evaluation criteria after three iterations, the system will return a default message in the Response field:
- Sample Data: Download the sample data from the given link.https://drive.google.com/file/d/1E6eUZjC0iSVmBX4fRyvqIrrXRY83gJAT/view?usp=drive_link
- Sample Query: For initial testing you can start with below queries.
- What is the ‘ratchet theory’ as discussed in the context of Katzenbach v. Morgan?
- What is the purpose of the exclusionary rule as applied by the Warren Court?
- What was the outcome of Christy Brzonkala’s lawsuit under the Violence Against Women Act?
- What is the process for electing the President and Vice President of the United States?